Ollie Glass
Understanding and managing uncertainty in data science projects
29th July 2018
Most data science projects involve creating predictive or explanatory models. Model building usually requires several rounds of researching approaches and techniques, collecting and processing data, and testing different model architectures and parameters. The accuracy and effectiveness of a model generally increases with trial, error and improvement, but it can’t be known in advance how long this research will take or the results it will bring.
How can you manage this uncertainty when you’re leading a project?
Some teams limit research to a fixed amount of time. This is risky, research could be stopped and considered a failure when breakthroughs were only days away. Giving machine learning projects no deadline also creates problems. I’ve seen projects run on for months without clear outputs or stopping criteria, draining resources, morale and appetite for machine learning in organisations.
In this piece I’ll show two approaches I use to estimate research time and evaluate outcomes. I’ll explain how I communicate this to clients and build a shared understanding about time, costs and outcomes.
Model accuracy and business value
Consider a new product feature that requires machine learning. What’s the minimum level of accuracy required from the ML model for the feature to satisfy users, and how much value does the it create for them and the business? If model accuracy increases above this minimum, does value keep increasing with it?
Imagine building a model to predict a quality score for images. These quality scores will be used in an image search engine, enabling it to show better images first and improve the search experience for users.
The search engine by itself has no sense of image quality, so before the model has been created its results are effectively in random order. Random is therefore the minimum accuracy level any model has to beat to make an impact - not always an easy or achievable target!
If a model improves beyond random, search results and user experience will become noticeably better. But at higher levels of accuracy when users are already getting good results and finding what they need most of the time, further improvements to the model will have less impact.
The value of different accuracy levels could be estimated and described like this:
| Model accuracy | Value |
| <50% | No value, no better than random. Doesn’t improve search results. |
| 51-80% | All improvements are valuable and have a clear impact on search quality. |
| 81-90% | Most results are already well ordered, most users are clicking on items in the first page of results. Further improvements are less important. |
| >91% | Most all users click one of the top 10 results, almost no value in any further improvements. |
I like to discuss and draw up this accuracy-value table with clients. Many people assume that anything less than a very accurate system isn’t valuable, this exercise lets me unpack and examine the assumptions behind that. If you think creatively, you can often find ways to make even quite low accuracy models valuable, perhaps by using them to power a different feature, or using them on a different data set.
Estimating the cost of research
How much work is required to reach the minimum accuracy level and start creating value, or to go beyond that? This can’t be known for certain in advance. You can look at the results others have achieved, and sometimes see the resources that were spent to achieve them, then use this as a rough estimate. But your requirements will depend on your situation - what you want to model, how complex it is and the approach you’re taking.
As a very rough guide, fifty to a thousand records will let you get started with many machine learning techniques, and anywhere from two weeks to a month is often enough to show if reaching minimum accuracy is possible. Adding more time and data usually helps, up to a point.
As work progresses on building a model, diagnostic tests (like learning curves) will give an indication of how valuable more work or data will be. You’ll also know if you have many approaches left to try, or are approaching the state of the art and running out of ideas.
Consider this curve:
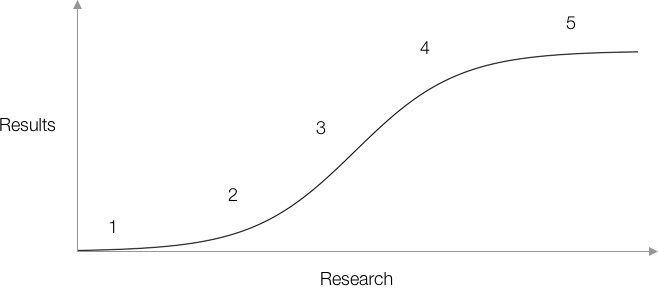
Starting from 1 you collect some data, build a model and see results at 2. It can be especially complicated to understand the problem and find ways to fit it into machine learning terms, so the journey from 1 to 2 can be particularly difficult.
Progress becomes easier as you keep researching and building understanding, developing a set of new approaches to try and working through them, climbing the slope at 3. 4 is the point of diminishing returns. As the obvious lines of enquiry dry up, new techniques become harder to find, can take longer to apply to your project and to work through. At 5 you’ve exhausted the capabilities of your research, perhaps reaching the state of the art, and can go no further.
The curve is a simple rule of thumb, progress is never this clear or smooth. It’s not always apparent when you’ve reached point five, you may be at a temporary plateau. Changing the approach, modelling technique or how the data is prepared could bring unexpected breakthroughs. But whatever the specific twists and turns of the research look like, in the long term I find many projects follow this pattern.
As a data scientist, even explaining that new developments are coming more quickly or slowly than before can be helpful to others. Giving an estimate of the time, cost and progress you expect from a new round of research gives some visibility and legibility to the process, helping build shared understanding.
Using these ideas in practice
Now we have an understanding of the value of research and a way to estimate the time and cost of progress. This clears up much of the uncertainty about managing research that we started with. We’ve also split the research into two stages: reaching minimum accuracy and improving beyond that.
Minimum accuracy is a crucial milestone. If it’s reached, the research can be considered a success. It becomes possible for the model to deliver value even if no further improvements are made, and so the wider project has been substantially derisked.
Part of my pre-sale work includes forming the best estimate I can of how likely it will be to achieve this and how long I expect it to take. I draw on the machine learning literature, case studies, articles and blog posts, other data scientists in my network and my past experience. I share my findings and estimates with clients, if the risk is acceptable to everyone we’ll start a project.
After reaching minimum accuracy, using the research-results and the accuracy-value table lets me estimate the work for the next improvement and the value it will bring. I share a high level summary and recommendations with clients, and can go into specifics to let them understand the options and make informed decisions about how much project time to dedicate to research or other areas.
Summing up
Clients are looking for product and business outcomes, not just model accuracy. Data scientists need to consider how research time and model accuracy makes different outcomes possible, and explain the relationship between them.
Many projects can be delivered successfully with relatively simple methods and modest levels of accuracy. You rarely need to achieve state of the art accuracy levels or use cutting edge modelling techniques. Further accuracy may be nice to have, but is rarely essential.
The work of building and communicating this understanding is collaborative, but the data scientist must lead it. Popular understanding of data science is still very low, it’s not reasonable to expect clients to know that rapidly delivering a low accuracy models is often possible, and a better fit for their needs, budgets and timelines.
Further reading
Return to the introductory piece, data science today
Read about managing data science projects.